Seite 1 von 1
Zeichensatz aus Datei [ERLEDIGT]
Verfasst: Do, 06. Feb 2020 17:47
von Koverhage
Habe bei der Suche nichts gescheites gefunden.
Ich muss des Öfteren Textdateien einlesen.
Normalerweise enthalten die DOS/OEM oder WIN/ANSI Zeichensätze.
Jetzt habe ich eine Datei die mit einem DOS Editor
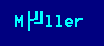
- DOS Editor
- 2020-02-06_170149.png (355 Bytes) 7775 mal betrachtet
Mit Windows Editor (ANSI Zeichensatz)
Müller
Mit Ultra Edit
Müller (wenn ich das hier einfüge, Original wie Bild)
Re: Zeichensatz aus Datei
Verfasst: Fr, 07. Feb 2020 7:20
von brandelh
das sieht für mich nach UTF8 kodiertem Text aus, einfach mal umsetzen was passiert.
PS: mit Notepad+ kann man alle möglichen Dateien öffnen und dann nachsehen welcher Zeichensatz verwendet wird (unter Codierung).
Re: Zeichensatz aus Datei
Verfasst: Fr, 07. Feb 2020 8:09
von Koverhage
Danke, sehr hilfreich. Musste zwar ein wenig suchen weil bei mir Kodierung steht

Re: Zeichensatz aus Datei [ERLEDIGT]
Verfasst: Fr, 07. Feb 2020 8:12
von Koverhage
Da müsste ich mir ja mal den Quellcode ziehen. Die Funktion zum Feststellen des Zeichensatzes könnte für mich sehr hilfreich sein.
Re: Zeichensatz aus Datei [ERLEDIGT]
Verfasst: Fr, 07. Feb 2020 8:49
von Marcus Herz
"Echte" Unicode Dateien haben einen Offset am Anfang, den clevere Editoren ausblenden (z.B. Notepad) aber den Zeichensatz erkennen:
UFT8:  xEF BB BF
UTF16;ÿþ xFF FE
oder
þÿ xFE FF
Man sieht das z.B. bei Combit LST Dateien am Anfang: sind UTF 8 Codiert
Re: Zeichensatz aus Datei [ERLEDIGT]
Verfasst: Fr, 07. Feb 2020 8:53
von Jan
BOM = Byte Order Mark
Machen aber dummerweise nicht alle Programme, ist also kein absolut sicheres Zeichen.
Jan
Re: Zeichensatz aus Datei [ERLEDIGT]
Verfasst: Fr, 07. Feb 2020 9:30
von Koverhage
Ich mache das jetzt so
Erst prüfe ich auf chr(195)
Wenn vorhanden dann auf
195+159 usw.
das reicht erstmal für meine Zwecke aus
Re: Zeichensatz aus Datei [ERLEDIGT]
Verfasst: Fr, 07. Feb 2020 9:49
von brandelh
Wenn die Dateien von Linux, Unix oder Apple kommen können, muss man den Zeilen Trenner abfragen, so wie ich in meiner HBTextReader() Klasse:
Code: Alles auswählen
METHOD HBTxtReader:IsCrLf()
RETURN (::cCRLF == chr(13)+chr(10))
METHOD HBTxtReader:IsUnix()
RETURN (::cCRLF == chr(10))
METHOD HBTxtReader:IsMac()
RETURN (::cCRLF == chr(13))
Die Reihenfolge der Byte Order hängt vom Betriebssystem bzw. auch vom Prozessor ab.
Re: Zeichensatz aus Datei [ERLEDIGT]
Verfasst: Do, 12. Mär 2020 19:16
von Bernd Reinhardt
Hallo
Ich mache aktuell viel über XML (UTF8) und da auch immer das Problem mit den doppelten Character pro zeichen.
Hab jetzt mal einen Versuch mit UTF82Char() (xBase 2.0) gemacht und das sieht ganz gut aus.
Gruß
Bernd